概述
SQL 标准组织在 2014 年 3 月已经完成了 SQL/JSON 标准草案(DM32.2 SQL/JSON Proposals, part1, part2) slides。完整的草案在 2016 年 12 月正式被采纳为标准,即 SQL:2016。2015 年 8 月,MySQL 从 5.7.8 版本开始增加了对 JSON 类型的支持, 详见 mysqld-5-7-8-json。
MySQL 对 JSON 的支持,设计文档主要是 WL#7909: Server side JSON functions,另外还有 WL#8132: JSON datatype and binary storage format、WL#8249: JSON comparator、WL#8607: Inline JSON path expressions in SQL 等。在 MySQL 开始 WL#7909 之时,SQL/JSON 标准草案已经公开,WL#7909 中也提及了这份标准,但是如果拿 MySQL 提供 JSON 的功能与 SQL:2016 比较,可以发现 MySQL 虽然融入了部分的设计,但并没有完全参考标准,定义的 JSON 函数多数有区别。
JSON 优势
- 1.JSON 数据类型,会自动校验数据是否为 JSON 格式,如果不是 JSON 格式数据,则会报错。
- 2.MySQL 提供了一组操作 JSON 数据的内置函数。
- 3.优化的存储格式,存储在 JSON 列中的 JSON 数据被转换成内部的存储格式。其允许快速读取。
- 4.可以修改特定的键值,(之前在 MySQL 中存储过 JSON 格式字符串,每次修改一个值,都要将整个 JSON 字符串更新一遍。)
JSON 使用场景
- 1.存储些不是特别关键且不常修改的数据,查询后主要用于展示。比如用户的自定义配置
- 2.适应表结构的动态变化
- 3.避免无意义数据,比如字段 is_admin 只有少数用户拥有,没有必要新增一列进行存储
安装 MySQL8.0
# 停止服务
docker stop mysql-server; docker rm mysql-server; trash ~/packages/data/mysql;
# 启动服务
docker run -d -p 3306:3306 -v ~/packages/data/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=root123456 -e MYSQL_USER=admin -e MYSQL_PASSWORD=admin123456 --name mysql-server mysql:8 --character-set-server=utf8mb4 --collation-server=utf8mb4_bin;
# 等待初始化完成
sleep 20;
# 初始化管理员账户
docker exec -it mysql-server sh -c "mysql -uroot -proot123456 -e \"GRANT ALL ON *.* TO 'admin'@'%' WITH GRANT OPTION;flush privileges;\""
# Mac下安装客户端
brew install mysql-client
# 或者安装Web UI
docker run -d -p 8088:80 --link mysql-server:db -e PMA_PORT=3306 --name mysql-admin phpmyadmin/phpmyadmin
设置快捷命令
通过 MySQL 提供的 --execute 参数可以在不进入交互式命令行的情况下执行 SQL。通过 Python 封装执行建表、存储过程等复杂 SQL 的函数。
# 设置密码
%env MYSQL_PWD=admin123456
%env MYSQL_HOST=127.0.0.1
# 创建数据库
!/usr/local/opt/mysql-client/bin/mysql -h ${MYSQL_HOST} -uadmin -e 'create database if not exists test;'
# 设置快捷命令
%alias mymysql /usr/local/opt/mysql-client/bin/mysql -h ${MYSQL_HOST} --database=test -uadmin
import subprocess
def run_sql(sql, is_log_cmd=False, is_log_sql=False):
cmd = "/usr/local/opt/mysql-client/bin/mysql -h ${MYSQL_HOST} --database=test -uadmin -e '%s'" % sql
if is_log_cmd:
print("cmd: %s" % cmd)
if is_log_sql:
print("mysql> %s" % sql)
subprocess.call(cmd, shell=True)
%mymysql -e "show databases;"
env: MYSQL_PWD=admin123456
env: MYSQL_HOST=127.0.0.1
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| test |
+--------------------+
插入 JSON 数据
类似 varchar,设置 JSON 主要将字段的 type 是 json, 不能设置长度,可以是 NULL 但不能有默认值。
# 创建表
run_sql("""
drop table if exists t1;
create table if not exists t1 (
`id` int(10) not null auto_increment,
`attr` json,
`tags` json,
primary key (`id`)
);
""")
# 查看表结构
%mymysql -e 'show columns from t1;'
# 插入测试数据
%mymysql -e 'insert into `t1` (attr, tags) values("{\"id\": 1, \"name\": \"seekplum\"}", "[1,2,3, \"a\", \"b\"]");'
%mymysql -e 'insert into `t1` (attr, tags) values (JSON_OBJECT("id", 2, "name", "hjd"), JSON_ARRAY(1,3,5));'
# 查询结果
%mymysql -e "select * from t1;"
+-------+------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| attr | json | YES | | NULL | |
| tags | json | YES | | NULL | |
+-------+------+------+-----+---------+----------------+
+----+-------------------------------+---------------------+
| id | attr | tags |
+----+-------------------------------+---------------------+
| 1 | {"id": 1, "name": "seekplum"} | [1, 2, 3, "a", "b"] |
| 2 | {"id": 2, "name": "hjd"} | [1, 3, 5] |
+----+-------------------------------+---------------------+
更多生成 JSON 值的函数请参考: http://dev.mysql.com/doc/refman/5.7/en/json-creation-functions.html
查询 JSON 数据
查询 json 中的数据用 column->path(等价于 JSON_EXTRACT(column, path)) 的形式,其中对象类型 path 这样表示 $.path, 而数组类型则是 $[index]
通过 JSON_TYPE() 可以查看属性的类型
%mymysql -e 'select id, JSON_TYPE(attr->"$.id"), attr->"$.id", attr->"$.name", tags->"$[0]" from t1;'
+----+-------------------------+--------------+----------------+--------------+
| id | JSON_TYPE(attr->"$.id") | attr->"$.id" | attr->"$.name" | tags->"$[0]" |
+----+-------------------------+--------------+----------------+--------------+
| 1 | INTEGER | 1 | "seekplum" | 1 |
| 2 | INTEGER | 2 | "hjd" | 1 |
+----+-------------------------+--------------+----------------+--------------+
%mymysql -e 'select id, attr->"$.name", JSON_UNQUOTE(attr->"$.name"), attr->>"$.name" from t1;'
+----+----------------+------------------------------+-----------------+
| id | attr->"$.name" | JSON_UNQUOTE(attr->"$.name") | attr->>"$.name" |
+----+----------------+------------------------------+-----------------+
| 1 | "seekplum" | seekplum | seekplum |
| 2 | "hjd" | hjd | hjd |
+----+----------------+------------------------------+-----------------+
%mymysql -e 'select id, JSON_EXTRACT(attr,"$.name"), JSON_UNQUOTE(JSON_EXTRACT(attr,"$.name")) from t1;'
+----+-----------------------------+-------------------------------------------+
| id | JSON_EXTRACT(attr,"$.name") | JSON_UNQUOTE(JSON_EXTRACT(attr,"$.name")) |
+----+-----------------------------+-------------------------------------------+
| 1 | "seekplum" | seekplum |
| 2 | "hjd" | hjd |
+----+-----------------------------+-------------------------------------------+
可以看到对应字符串类型的 attr->’$.name’ 中还包含着双引号,这其实并不是想要的结果,可以用 JSON_UNQUOTE 函数将双引号去掉,从 MySQL 5.7.13 起也可以通过这个操作符 ->> 这个和 JSON_UNQUOTE 是等价的
搜索 JSON 中的数据
因为 JSON 不同于字符串,所以如果用字符串和 JSON 字段比较,是不会相等的
%mymysql -e 'select * from t1 where attr="{\"id\": 1, \"name\": \"seekplum\"}";'
需要通过 CAST 将字符串转成 JSON 的形式
%mymysql -e 'select * from t1 where attr=CAST("{\"id\": 1, \"name\": \"seekplum\"}" as JSON);'
+----+-------------------------------+---------------------+
| id | attr | tags |
+----+-------------------------------+---------------------+
| 1 | {"id": 1, "name": "seekplum"} | [1, 2, 3, "a", "b"] |
+----+-------------------------------+---------------------+
通过 JSON 中的元素进行查询, 对象型的查询同样可以通过 column->path
%mymysql -e 'select * from t1 where attr->"$.name" = "seekplum";'
+----+-------------------------------+---------------------+
| id | attr | tags |
+----+-------------------------------+---------------------+
| 1 | {"id": 1, "name": "seekplum"} | [1, 2, 3, "a", "b"] |
+----+-------------------------------+---------------------+
%mymysql -e 'select * from t1 where attr->>"$.name" = "seekplum";'
+----+-------------------------------+---------------------+
| id | attr | tags |
+----+-------------------------------+---------------------+
| 1 | {"id": 1, "name": "seekplum"} | [1, 2, 3, "a", "b"] |
+----+-------------------------------+---------------------+
上面有提到 column->path 形式从 select 中查询出来的字符串是包含双引号的,但作为条件这里其实没什么影响,-> 和 -» 结果是一样的
要特别注意的是, column->path 的形式搜索 JSON 中的元素是严格区分变量类型的,比如说整型和字符串是严格区分的。column->>path 的形式搜索 JSON 中的元素是不区分变量类型的
%mymysql -e 'select * from t1 where attr->"$.id" = "1";'
%mymysql -e 'select * from t1 where attr->"$.id" = 1;';
+----+-------------------------------+---------------------+
| id | attr | tags |
+----+-------------------------------+---------------------+
| 1 | {"id": 1, "name": "seekplum"} | [1, 2, 3, "a", "b"] |
+----+-------------------------------+---------------------+
%mymysql -e 'select * from t1 where attr->>"$.id" = "1";'
+----+-------------------------------+---------------------+
| id | attr | tags |
+----+-------------------------------+---------------------+
| 1 | {"id": 1, "name": "seekplum"} | [1, 2, 3, "a", "b"] |
+----+-------------------------------+---------------------+
除了用 column->path 的形式搜索,还可以用 JSON_CONTAINS 函数,但和 column->path 的形式有点相反的是,JSON_CONTAINS 第二个参数是不接受整数的,无论 json 元素是整型还是字符串,否则会出现这个错误
%mymysql -e 'select * from t1 where JSON_CONTAINS(attr, 1, "$.id");';
ERROR 3146 (22032) at line 1: Invalid data type for JSON data in argument 1 to function json_contains; a JSON string or JSON type is required.
%mymysql -e 'select * from t1 where JSON_CONTAINS(attr, "1", "$.id");'
+----+-------------------------------+---------------------+
| id | attr | tags |
+----+-------------------------------+---------------------+
| 1 | {"id": 1, "name": "seekplum"} | [1, 2, 3, "a", "b"] |
+----+-------------------------------+---------------------+
更多搜索 JSON 值的函数请参考:http://dev.mysql.com/doc/refman/5.7/en/json-search-functions.html
更新 JSON
如果是整个 JSON 更新的话,和插入是类似
%mymysql -e 'update t1 set tags="[1,2,3,4]" where id=1;'
%mymysql -e 'select * from t1 where id=1;'
+----+-------------------------------+--------------+
| id | attr | tags |
+----+-------------------------------+--------------+
| 1 | {"id": 1, "name": "seekplum"} | [1, 2, 3, 4] |
+----+-------------------------------+--------------+
JSON_INSERT() 插入新值,但不会覆盖已经存在的值
%mymysql -e 'update t1 set attr=JSON_INSERT(attr, "$.name", "update_seekplum1111", "$.uri", "http://test.com") where id=1;'
%mymysql -e 'select * from t1 where id=1;'
+----+---------------------------------------------------------+--------------+
| id | attr | tags |
+----+---------------------------------------------------------+--------------+
| 1 | {"id": 1, "uri": "http://test.com", "name": "seekplum"} | [1, 2, 3, 4] |
+----+---------------------------------------------------------+--------------+
可以看到 name 没有被修改,但新元素 uri 已经添加进去了
JSON_SET() 插入新值,并覆盖已经存在的值
%mymysql -e 'update t1 set attr=JSON_SET(attr, "$.host", "www.test.com", "$.uri", "http://www.test.com") where id=1;'
%mymysql -e 'select * from t1 where id=1;'
+----+-------------------------------------------------------------------------------------+--------------+
| id | attr | tags |
+----+-------------------------------------------------------------------------------------+--------------+
| 1 | {"id": 1, "uri": "http://www.test.com", "host": "www.test.com", "name": "seekplum"} | [1, 2, 3, 4] |
+----+-------------------------------------------------------------------------------------+--------------+
JSON_REPLACE() 只替换存在的值
%mymysql -e 'update t1 set attr=JSON_REPLACE(attr, "$.name", "relace_seekplum", "$.domain", "seekplum.com") where id=1'
%mymysql -e 'select * from t1 where id=1;'
+----+--------------------------------------------------------------------------------------------+--------------+
| id | attr | tags |
+----+--------------------------------------------------------------------------------------------+--------------+
| 1 | {"id": 1, "uri": "http://www.test.com", "host": "www.test.com", "name": "relace_seekplum"} | [1, 2, 3, 4] |
+----+--------------------------------------------------------------------------------------------+--------------+
JSON_REMOVE() 删除 JSON 元素
%mymysql -e 'update t1 set attr=JSON_REMOVE(attr, "$.uri", "$.host") where id=1;'
%mymysql -e 'select * from t1 where id=1;'
+----+--------------------------------------+--------------+
| id | attr | tags |
+----+--------------------------------------+--------------+
| 1 | {"id": 1, "name": "relace_seekplum"} | [1, 2, 3, 4] |
+----+--------------------------------------+--------------+
MySQL JSON 相关函数
| 分类 | 函数 | 描述 |
|---|---|---|
| 创建JSON | JSON_ARRAY | 创建JSON数组 |
| JSON_OBJECT | 创建JSON对象 | |
| JSON_QUOTE | 将JSON转成JSON字符串类型 | |
| 搜索JSON | JSON_CONTAINS | 判断是否包含某个JSON值 |
| JSON_CONTAINS_PATH | 判断某个路径下是否包JSON值 | |
| JSON_EXTRACT | 提取JSON值 | |
| column->path | JSON_EXTRACT的简洁写法,5.7.9 开始支持 | |
| column->>path | JSON_UNQUOTE(column -> path)的简洁写法,5.7.13 开始支持 | |
| JSON_KEYS | 提取JSON中的键值为JSON数组 | |
| JSON_SEARCH | 按给定字符串关键字搜索JSON,返回匹配的路径 | |
| 修改JSON | JSON_APPEND | MySQL 5.7.9开始废弃,改名为JSON_ARRAY_APPEND |
| JSON_ARRAY_APPEND | 末尾添加数组元素,如果原有值是数值或JSON对象,则转成数组后,再添加元素 | |
| JSON_ARRAY_INSERT | 插入数组元素 | |
| JSON_INSERT | 插入值(插入新值,但不替换已经存在的旧值) | |
| JSON_MERGE | 5.7.22开始废弃,合并JSON数组或对象 | |
| JSON_MERGE_PATCH | 合并的JSON文件,免去重复键的值,5.7.22开始支持 | |
| JSON_MERGE_PRESERVE | 合并的JSON文件,保存重复键,5.7.22开始支持 | |
| JSON_REMOVE | 删除JSON数据 | |
| JSON_REPLACE | 替换值(只替换已经存在的旧值) | |
| JSON_SET | 设置值(替换旧值,并插入不存在的新值) | |
| JSON_UNQUOTE | 去除JSON字符串的引号,将值转成string类型 | |
| 返回JSON属性 | JSON_DEPTH | 返回JSON文档的最大深度 |
| JSON_LENGTH | 返回JSON文档的长度 | |
| JSON_TYPE | 返回JSON值得类型 | |
| JSON_VALID | 判断是否为合法JSON文档 | |
| JSON实用程序功能 | JSON_PRETTY | 提供漂亮的JSON值打印,5.7.22开始支持 |
| JSON_STORAGE_SIZE | 返回用于存储JSON文档的二进制表示形式的字节数,5.7.22开始支持 |
通配符
- 路径可以包含
*和**通配符:- .[*] 表示匹配某个 JSON 对象中所有的成员
- [*] 表示匹配某个 JSON 数组中的所有元素
- prefix**suffix 表示全部以 prefix 开始,以 suffix 结尾的路径。
- 如果路径在 JSON 文档中不存在数据,将返回 NULL。
%mymysql -e 'select json_extract("{\"a\": {\"b\": 1}, \"c\": {\"b\": 2}, \"d\": [3, 4, 5]}", "$.*");'
%mymysql -e 'select json_extract("{\"a\": {\"b\": 1}, \"c\": {\"b\": 2}, \"d\": [3, 4, 5]}", "$.d[*]");'
%mymysql -e 'select json_extract("{\"a\": {\"b\": 1}, \"c\": {\"b\": 2}}", "$**.b");'
+---------------------------------------------------------------------------------+
| json_extract("{\"a\": {\"b\": 1}, \"c\": {\"b\": 2}, \"d\": [3, 4, 5]}", "$.*") |
+---------------------------------------------------------------------------------+
| [{"b": 1}, {"b": 2}, [3, 4, 5]] |
+---------------------------------------------------------------------------------+
+------------------------------------------------------------------------------------+
| json_extract("{\"a\": {\"b\": 1}, \"c\": {\"b\": 2}, \"d\": [3, 4, 5]}", "$.d[*]") |
+------------------------------------------------------------------------------------+
| [3, 4, 5] |
+------------------------------------------------------------------------------------+
+-----------------------------------------------------------------+
| json_extract("{\"a\": {\"b\": 1}, \"c\": {\"b\": 2}}", "$**.b") |
+-----------------------------------------------------------------+
| [1, 2] |
+-----------------------------------------------------------------+
虚拟列
可以通过虚拟列对 JSON 类型的指定属性进行快速查询。之所以取名虚拟列,是因为与它对应的还有个存储列(stored column)。它们之间最大的区别是虚拟列只修改数据库的 metadata ,并不会真是的存储在硬盘上,读取的时候是实时计算的。存储列会把表达式的列真实的存储在硬盘上。
虚拟列的添加和删除都很快,在虚拟列上建立索引和传统的建立索引方式并没有区别,会提高虚拟列读取的性能,减慢整体插入的性能。虚拟列的特性结合 JSON 的路径表达式,可以方便的为用户提供高效的键值索引功能。
虚拟列限制
- 1.无法在虚拟列上添加主键
- 2.不能在虚拟列上创建全文索引和空间索引,这个在之后的版本有望解决。详见这里
- 3.虚拟列不能作为外键
- 4.创建虚拟列(也包括存储列)时不能使用非确定性(不可重复)的函数,比如
curtime() - 5.虚拟列的添加和删除只能在单独执行单个操作时完成,而不能在与其他表更改结合使用时就地或在线完成。此限制将在以后删除。
# 创建新表
run_sql("""
drop table if exists t2;
create table if not exists t2 (
id int not null primary key auto_increment,
attr json not null,
tags json not null,
vname varchar(50) generated always as (concat(`attr` ->> "$.name", `attr` ->> "$.age")) not null
);
""")
%mymysql -e 'show columns from t2;'
+-------+-------------+------+-----+---------+-------------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------------------+
| id | int | NO | PRI | NULL | auto_increment |
| attr | json | NO | | NULL | |
| tags | json | NO | | NULL | |
| vname | varchar(50) | NO | | NULL | VIRTUAL GENERATED |
+-------+-------------+------+-----+---------+-------------------+
插入测试数据
通过存储过程插入 1 万条测试数据
# 开启mysql存储函数
run_sql("""
show variables like "log_bin_trust_function_creators"; -- 查看是否开启存储函数
set global log_bin_trust_function_creators=1;
""")
# 删除并新创建存储过程
run_sql('''
drop procedure if exists insert_data;
delimiter $$
create procedure insert_data(in max_num int(10))
begin
declare i int default 0;
declare tag_total int default 1;
declare v_count int default 1;
declare age int default 1;
declare attr varchar(200) default "{}";
declare tags varchar(200) default "1";
repeat
set i=i+1;
set age=FLOOR(1 + RAND() * (100));
set attr = concat(concat("{""name"":""seekplum-",i),concat(""",""age"":", age),"}");
set tag_total=FLOOR(1 + RAND() * (10));
set v_count=2;
set tags="1";
while v_count <= tag_total do
set tags=concat(tags, ",", v_count);
set v_count = v_count + 1;
end while;
set tags=concat("[", tags, "]");
insert into t2 (id,attr,tags) values(null,attr,tags);
until i=max_num
end repeat;
commit;
end $$
delimiter ; -- 将语句的结束符号恢复为分号
''')
# 插入1万条数据
%mymysql -e 'call insert_data(10000);'
创建索引
MySQL 的 JSON 格式数据不能直接创建索引,但是可以变通一下,把要搜索的数据单独拎出来,单独一个数据列,然后在这个字段上创建一个索引。
# 删除索引
%mymysql -e 'alter table t2 drop index vname_index;'
# 查看执行计划
%mymysql -e 'explain select * from t2 where vname="seekplum-999";'
# 对虚拟列添加索引
%mymysql -e 'alter table t2 add index vname_index (vname);'
# 再次查看执行计划
%mymysql -e 'explain select * from t2 where vname="seekplum-999";'
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 9949 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | t2 | NULL | ref | vname_index | vname_index | 202 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------------+---------+-------+------+----------+-------+
JSON 比较与排序
JSON 值可以使用=, <, <=, >, >=, <>, !=, <=>等操作符,BETWEEN, IN, GREATEST, LEAST 等操作符现在还不支持。JSON 值使用的两级排序规则,第一级基于 JSON 的类型,类型不同的使用每个类型特有的排序规则。
JSON 类型按照优先级从高到低为
BLOB
BIT
OPAQUE
DATETIME
TIME
DATE
BOOLEAN
ARRAY
OBJECT
STRING
INTEGER, DOUBLE
NULL
优先级高的类型大,不用再进行其他的比较操作;如果类型相同,每个类型按自己的规则排序。具体的规则如下:
-
- BLOB/BIT/OPAQUE: 比较两个值前 N 个字节,如果前 N 个字节相同,短的值小
-
- DATETIME/TIME/DATE: 按照所表示的时间点排序
-
- BOOLEAN: false 小于 true
-
- ARRAY: 两个数组如果长度和在每个位置的值相同时相等,如果不想等,取第一个不相同元素的排序结果,空元素最小
[] < [“a”] < [“ab”] < [“ab”, “cd”, “ef”] < [“ab”, “ef”]
-
- OBJECT: 如果两个对象有相同的 KEY,并且 KEY 对应的 VALUE 也都相同,两者相等。否则,两者大小不等,但相对大小未规定。
-
- STRING: 取两个 STRING 较短的那个长度为 N,比较两个值 utf8mb4 编码的前 N 个字节,较短的小,空值最小
“a” < “ab” < “b” < “bc”
-
- INTEGER/DOUBLE: 包括精确值和近似值的比较,稍微有点复杂,可能出现与直觉相悖的结果,具体参见官方文档相关说明。
任何 JSON 值与 SQL 的 NULL 常量比较,得到的结果是 UNKNOWN。对于 JSON 值和非 JSON 值的比较,按照一定的规则将非 JSON 值转化为 JSON 值,然后按照以上的规则进行比较。
JSON 二进制格式
MySQL 的内部实现中,保存到数据库的 JSON 数据 并不是以 JSON 文本存储的,而是二进制的格式,具体可以参见 WL#8132: JSON datatype and binary storage format. GitHub 源码见json_binary.h 或者查看 MySQL 的源代码文档 doxygen。
对 MySQL 的 JSON 二进制格式,有一点需要注意,为了能利用二分搜索快速定位键,存入数据库的 JSON 对象的键是被排序过的。
# 清空 t1 表数据
%mymysql -e 'truncate t1;'
%mymysql -e 'insert into t1 (attr, tags) values ("{\"b\": 2, \"d\": 4, \"a\": {\"y\": 2, \"x\": 1}, \"c\": \"c\"}", "[1,4,3,2]");'
%mymysql -e 'select * from t1';
+----+---------------------------------------------------+--------------+
| id | attr | tags |
+----+---------------------------------------------------+--------------+
| 1 | {"a": {"x": 1, "y": 2}, "b": 2, "c": "c", "d": 4} | [1, 4, 3, 2] |
+----+---------------------------------------------------+--------------+
上面的 SQL 可以看到,insert 写入时键并没有按次序排列,而用 select 将 JSON 数据反序列化读出,发现实际保存的键是有序的。排序规则是,先按字符串长度排序,若长度相同按字母排序。同样的,键关联的值,按键排序后的次序排列。对键排序,显然只能针对 JSON 对象,若要存储 JSON 数组,值按索引位置排序。
图和内容来源 MySQL 5.7 JSON 实现简介
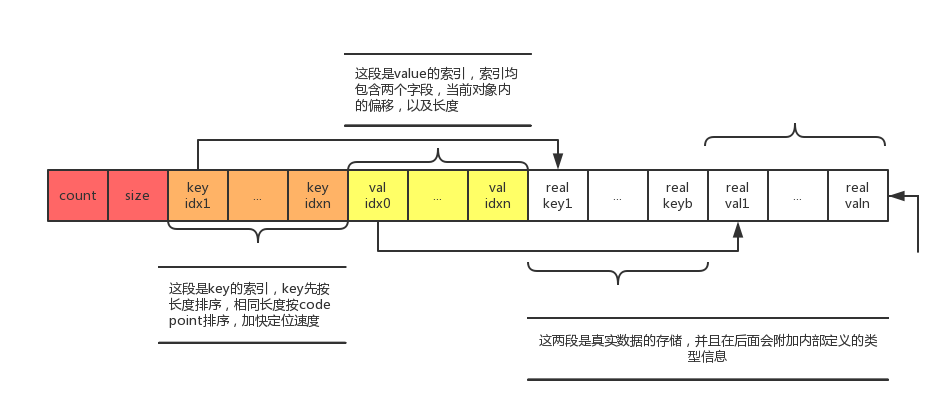
JSON 文档本身是层次化的结构,因此 MySQL 对 JSON 存储也是层次化的、对于每一级对象,存储的最前面为存放当前对象的元素个数,以及整体大小。
-
- JSON 对象的 Key 索引(图中橙色部分)都是排序好的,先按长度排序,长度相同的按照 code point 排序;Value 索引(图中黄色部分)根据对应的 Key 的位置依次排列,最后面真实的数据存储(图中白色部分)也是如此
-
- Key 和 Value 的索引对存储了对象内的偏移和大小,单个索引的大小固定,可以通过简单的算术跳转到距离为 N 的索引
-
- 通过 MySQL5.7.16 源代码可以看到,在序列化 JSON 文档时,MySQL 会动态检测单个对象的大小,如果小于 64KB 使用两个字节的偏移量,否则使用四个字节的偏移量,以节省空间。同时,动态检查单个对象是否是大对象,会造成对大对象进行两次解析,源代码中也指出这是以后需要优化的点
-
- 现在受索引中偏移量和存储大小四个字节大小的限制,单个 JSON 文档的大小不能超过 4G;单个 KEY 的大小不能超过两个字节,即 64K
-
- 索引存储对象内的偏移是为了方便移动,如果某个键值被改动,只用修改受影响对象整体的偏移量
-
- 索引的大小现在是冗余信息,因为通过相邻偏移可以简单的得到存储大小,主要是为了应对变长 JSON 对象值更新,如果长度变小,JSON 文档整体都不用移动,只需要当前对象修改大小
-
- 现在 MySQL 对于变长大小的值没有预留额外的空间,也就是说如果该值的长度变大,后面的存储都要受到影响
-
- 结合 JSON 的路径表达式可以知道,JSON 的搜索操作只用反序列化路径上涉及到的元素,速度非常快,实现了读操作的高性能
-
- 不过,MySQL 对于大型文档的变长键值的更新操作可能会变慢,可能并不适合写密集的需求
ORM
ORM(Object Relational Mapping) 对象关系映射,是一种为了解决面向对象与关系数据库存在的互不匹配的技术。简单的说,ORM 就是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中。
Peewee
Peewee 是一个简单而小型的 ORM。它几乎没有(但富有表现力)概念,使其易于学习且使用直观。Github 地址
优点
易于使用; 轻量级实现; 使其易于与任何 Web 框架集成
缺点
不支持自动架构迁移 多对多查询的编写不直观
示例
# -*- coding: utf-8 -*-
import json
from datetime import datetime
from peewee import Model, PrimaryKeyField, IntegerField, DateTimeField
from peewee import fn
from playhouse.db_url import connect, Cast
from playhouse.mysql_ext import JSONField
db = connect("mysql+pool://admin:admin123456@127.0.0.1:3306/test", max_connections=10, stale_timeout=300)
class BaseModel(Model):
class Meta:
database = db
class Template(BaseModel):
id = PrimaryKeyField()
timestamp = DateTimeField(default=datetime.now)
group = IntegerField()
desc = JSONField(default=[])
attr = JSONField(default={})
class Meta:
db_table = 'template'
indexes = (
(('group',), False),
)
def to_dict(self):
data = {}
for column, _ in self._meta.columns.items():
data[column] = getattr(self, column)
return data
def __repr__(self):
data = self.to_dict()
if isinstance(data["timestamp"], datetime):
data["timestamp"] = data["timestamp"].strftime("%Y-%m-%d %H:%M:%S")
return json.dumps(data, ensure_ascii=False, indent=2)
__str__ = __repr__
def create_tables():
db.connect()
db.drop_tables([Template])
db.create_tables([Template])
db.close()
def create_data():
data = Template.create(group=1, desc=[{
"x": 500,
"y": 500,
"o": 100,
"a": 0,
"w": 1000,
"h": 1000
}], attr={
"id": 1,
"official": 1,
"flag": 2,
"score": 737,
})
print("create_data data:", data)
def update_data():
info = {
"x": 194,
"y": 68,
"o": 100,
"a": 0,
"w": 388,
"h": 136
}
query = Template.update(group=2,
desc=fn.json_array_insert(Template.desc, "$[1]", Cast(json.dumps(info), "json")),
attr=fn.json_insert(Template.attr, "$.thumbnail", "/uploaded/i1/xxx.jpg")
).where(Template.group == 1, fn.json_contains(Template.desc, "500", "$[0].x"))
count = query.execute()
assert count == 1
for temp in Template.select().where(Template.group == 2):
print("template:", temp)
def main():
create_tables()
create_data()
update_data()
if __name__ == '__main__':
main()
create_data data: {
"id": 1,
"timestamp": "2020-08-13 15:00:08",
"group": 1,
"desc": [
{
"x": 500,
"y": 500,
"o": 100,
"a": 0,
"w": 1000,
"h": 1000
}
],
"attr": {
"id": 1,
"official": 1,
"flag": 2,
"score": 737
}
}
template: {
"id": 1,
"timestamp": "2020-08-13 15:00:08",
"group": 2,
"desc": [
{
"a": 0,
"h": 1000,
"o": 100,
"w": 1000,
"x": 500,
"y": 500
},
{
"a": 0,
"h": 136,
"o": 100,
"w": 388,
"x": 194,
"y": 68
}
],
"attr": {
"id": 1,
"flag": 2,
"score": 737,
"official": 1,
"thumbnail": "/uploaded/i1/xxx.jpg"
}
}
SqlAlchemy
SQLAlchemy 是 Python SQL 工具箱和对象关系映射器,它为应用程序开发人员提供了 SQL 的全部功能和灵活性。SQLAlchemy 提供了一整套知名的企业级持久性模式,旨在高效,高性能地进行数据库访问,并改编为简单的 Pythonic 域语言。Github 地址
优点
企业级 API; 使代码健壮且适应性强; 设计灵活; 使编写复杂查询变得轻而易举
缺点
工作单元概念并不常见; 重量级的 API; 导致漫长的学习曲线
示例
# -*- coding: utf-8 -*-
import json
from contextlib import contextmanager
from datetime import datetime
from sqlalchemy import func as sa_func
from sqlalchemy import Column, Integer, JSON, DateTime
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.schema import MetaData
engine_str = 'mysql+mysqldb://admin:admin123456@127.0.0.1:3306/test'
engine = create_engine(engine_str, pool_size=5, pool_recycle=3600,
connect_args={"use_unicode": True, "charset": "utf8mb4"})
Session = sessionmaker(bind=engine, autocommit=True, autoflush=False, expire_on_commit=False)
metadata = MetaData(bind=engine)
class ModelMixin(object):
id = Column(Integer, primary_key=True, autoincrement=True, nullable=False)
timestamp = Column(DateTime, default=datetime.utcnow, doc="创建时间utc")
def to_dict(self):
"""返回一个dict格式"""
result = {}
columns = self.__table__.columns.keys()
for column in columns:
result[column] = getattr(self, column)
return result
def __repr__(self):
data = self.to_dict()
if isinstance(data["timestamp"], datetime):
data["timestamp"] = data["timestamp"].strftime("%Y-%m-%d %H:%M:%S")
return json.dumps(data, ensure_ascii=False, indent=2)
__str__ = __repr__
Entity = declarative_base(name="Entity", metadata=metadata, cls=ModelMixin)
class Template(Entity):
__tablename__ = "template2"
group = Column(Integer, doc="分组ID")
desc = Column(JSON, default=[], doc="作图信息")
attr = Column(JSON, default={}, doc="基本属性")
@contextmanager
def open_session():
"""可以使用with 上下文,在with结束之后自动commit
"""
session = Session()
session.begin()
try:
yield session
session.commit()
except Exception as e:
session.rollback()
raise e
finally:
session.close()
def create_tables():
metadata.drop_all(engine)
metadata.create_all(engine)
def create_data():
with open_session() as session:
desc = [{
"x": 500,
"y": 500,
"o": 100,
"a": 0,
"w": 1000,
"h": 1000
}]
attr = {
"id": 1,
"official": 1,
"flag": 2,
"score": 737,
}
template = Template(group=1, desc=desc, attr=attr)
session.add(template)
print("create_data template:", template)
def update_data():
# 修改普通数据
with open_session() as session:
query = session.query(Template).filter(Template.group == 1,
sa_func.json_contains(Template.desc, "500", "$[0].x"))
template = query.one()
template.group = 2
# 修改 JSON 数组和对象 数据, 需要显示的转换成JSON
# 如果路径标识数组元素,则将相应的值插入该元素位置,然后将任何后续值向右移动。如果路径标识了超出数组末尾的数组位置,则将值插入到数组末尾。
update_info = {
"desc": sa_func.json_array_insert(Template.desc, '$[1]', sa_func.cast({
"x": 194,
"y": 68,
"o": 100,
"a": 0,
"w": 388,
"h": 136
}, JSON)),
"attr": sa_func.json_insert(Template.attr, "$.thumbnail", "/uploaded/i1/xxx.jpg")
}
with open_session() as session:
count = session.query(Template).filter(Template.group == 2).update(
update_info, synchronize_session=False)
assert count == 1
with open_session() as session:
for temp in session.query(Template).filter(Template.group == 2).all():
print(temp)
def main():
create_tables()
create_data()
update_data()
if __name__ == '__main__':
main()
create_data template: {
"id": null,
"timestamp": null,
"group": 1,
"desc": [
{
"x": 500,
"y": 500,
"o": 100,
"a": 0,
"w": 1000,
"h": 1000
}
],
"attr": {
"id": 1,
"official": 1,
"flag": 2,
"score": 737
}
}
{
"id": 1,
"timestamp": "2020-08-13 07:00:10",
"group": 2,
"desc": [
{
"a": 0,
"h": 1000,
"o": 100,
"w": 1000,
"x": 500,
"y": 500,
},
{
"a": 0,
"h": 136,
"o": 100,
"w": 388,
"x": 194,
"y": 68,
}
],
"attr": {
"id": 1,
"flag": 2,
"score": 737,
"official": 1,
"thumbnail": "/uploaded/i1/xxx.jpg"
}
}
总结
MySQL 中的 JSON 提供的功能比较丰富,基本可以满足日常需要的使(索引、增删改查等)。从我们目前项目使用情况来看,还没有遇到使用 MySQL 的痛点,Python 的主流 ORM(Peewee, SqlAlchemy) 都支持使用 JSON 相关功能,在后续新业务中可以进行尝试使用。
关于 MySQL 的二进制存储部分,准备不足,只能进行浅显的介绍,后续有机会再对这部分进行深入学习。

