前言
本文主要是对Tornado框架的目录结构进行一个梳理和一个简单的说明,同时补充异步、阻塞等相关概念。不涉及到具体代码。
版本信息
- 分支: branch5.1
- tag: v5.1.1
- commit id: cc2cf078a39abec6f8d181f76a4e5ba9432364f3
目录结构
➜ tornado git:(branch5.1) ✗ tree -L 1
.
├── LICENSE # license说明
├── MANIFEST.in # 打包配置文件
├── README.rst # 自述文件
├── .travis.yml # Travis CI的配置文件
├── appveyor.yml # AppVeyor 持续集成的托管平台配置
├── codecov.yml # Codecov代码覆盖率配置
├── demos # 使用示例
├── docs # 文档目录
├── maint # 开发中使用的工具和脚本
├── runtests.sh # 测试入口脚本
├── setup.cfg # 构建bdist_wheel时参数
├── setup.py # 安装入口
├── tornado # 源码文件
└── tox.ini # tox的配置文件,目的是自动化和标准化 Python 的测试工作
4 directories, 10 files
➜ tornado git:(branch5.1) ✗ tree tornado -L 1
tornado
├── __init__.py # 版本信息
├── _locale_data.py # 语言映射关系数据
├── auth.py # 使用OpenId和OAuth进行第三方登录
├── autoreload.py # 生产环境中自动检查代码更新
├── concurrent.py # concurrent线程/进程池三方库
├── curl_httpclient.py # 使用pycurl的非阻塞HTTP客户机实现
├── escape.py # HTML,JSON,URLs等的编码解码和一些字符串操作
├── gen.py # 一个基于生成器的接口,使用该模块保证代码异步运行
├── http1connection.py # HTTP/1.x的客户端和服务器实现。
├── httpclient.py # 一个无阻塞的HTTP服务器实现
├── httpserver.py # 一个无阻塞的HTTP服务器实现
├── httputil.py # 分析HTTP请求内容
├── ioloop.py # 核心的I/O循环
├── iostream.py # 对非阻塞式的 socket 的简单封装,以方便常用读写操作
├── locale.py # 国际化支持
├── locks.py # 自定义的锁模块
├── log.py # 日志记录模块
├── netutil.py # 一些网络应用的实现,主要实现TCPServer类
├── options.py # 解析终端参数
├── platform # 在Tornado上运行为Twisted实现的代码
├── process.py # 多进程实现的封装
├── queues.py # 非线程安全的异步队列
├── routing.py # 路由实现
├── simple_httpclient.py# 非阻塞的http客户端
├── speedups.c # 加速器,C代码
├── speedups.pyi # 加速器,由speedups.c转换而来
├── stack_context.py # 用于异步环境中对回调函数的上下文保存、异常处理
├── tcpclient.py # 一个非阻塞,单线程TCP客户端
├── tcpserver.py # 一个非阻塞,单线程TCP服务器
├── template.py # 模版系统
├── test # 单元测试,测试框架为unittest
├── testing.py # 支持自动化测试的类
├── util.py # 工具函数
├── web.py # 包含web框架的大部分主要功能,包含RequestHandler和Application两个重要的类
├── websocket.py # 实现和浏览器的双向通信
└── wsgi.py # 与其他python网络框架/服务器的相互操作
2 directories, 34 files
➜ tornado git:(branch5.1)
源码结构
模块间依赖
通过snakefood的分析,可知模块间的依赖还是非常复杂的。
框架设计模型
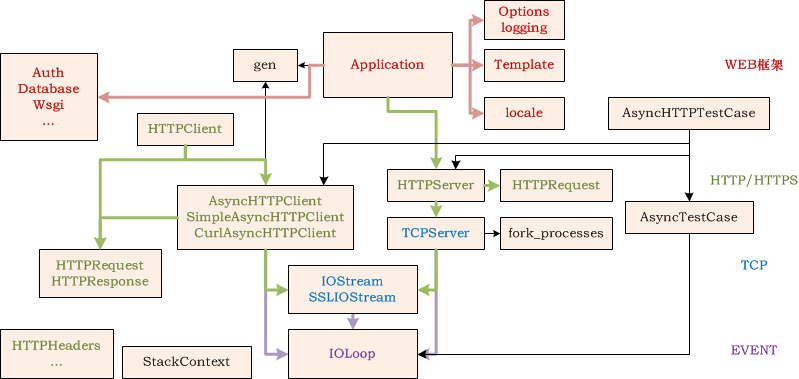
从上面的图可以看出,Tornado 不仅仅是一个WEB框架,它还完整地实现了HTTP服务器和客户端,在此基础上提供WEB服务。它可以分为四层:
- 最底层的EVENT层处理IO事件;
- TCP层实现了TCP服务器,负责数据传输;
- HTTP/HTTPS层基于HTTP协议实现了HTTP服务器和客户端;
- 最上层为WEB框架,包含了处理器、模板、数据库连接、认证、本地化等等WEB框架需要具备的功能。
同步/非同步
同步和异步针对应用程序来,关注的是消息通信机制,程序中间的协作关系。
- 同步
执行一个操作之后,等待结果,然后才继续执行后续的操作。同步需要主动读写数据,在读写数据过程中还是会阻塞。
- 异步
执行一个操作后,可以去执行其他的操作,然后等待通知再回来执行刚才没执行完的操作。由操作系统内核完成数据的读写。
阻塞/非阻塞
阻塞与非阻塞更关注的是单个进程的执行状态。进程/线程访问的数据是否就绪,进程/线程是否需要等待。
- 阻塞
进程给CPU传达一个任务之后,一直等待CPU处理完成,然后才执行后面的操作。
- 非阻塞
进程给CPU传达任我后,继续处理后续的操作,隔断时间再来询问之前的操作是否完成。这样的过程其实也叫轮询。
缓存IO
缓存IO,也被称为标准IO,大多数文件系统默认IO操作都是缓存IO,在Linux的缓存IO机制中,操作系统会将IO的数据缓存在文件系统的页缓存(page cache)中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间
- 缓存IO的缺点
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的
阻塞式IO
耗时型任务一般分为两类:CPU耗时型任务和IO耗时型任务。CPU指一般的代码运算执行过程,IO一般分为两大类,计算型IO和阻塞式IO。如果仅有一个线程,那么同一时刻只能有一个任务在计算,但如果是阻塞式IO,它可以让它先阻塞掉,然后去计算其他的任务,等到内核告诉程序那边没有被阻塞了就、再回到之前的地方进行之后的运算。
linux下,可以通过设置socket使其变为non-blocking。nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有。
Tornado异步原理
Tornado的异步实现就是将当前请求的协程暂停,等待其返回结果,在等待的过程中当前请求不能继续往下执行,但是如果有其他请求(同样是一个协程),只要不也是阻塞式IO,那么就会直接去处理其他的请求了。
部署
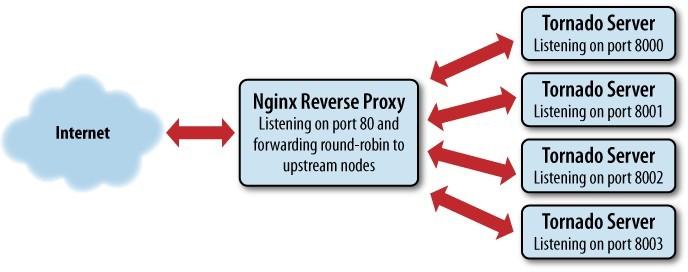
如上图所示,nginx + 多实例结合,nginx作为反向代理,后台以不同端口启动多个Tornado web服务。

